Buckle up for BenchmarkDotNet
As software developers, we sometimes find ourselves optimizing the code to squeeze that last bit of performance right ?
While we can eventually achieve optimal code.
Wouldn’t it be great, if we have an easy way to produce scientific and repeatable benchmarks ?
Why do we need benchmarks ?
Modern software development for the most part goes through an iterative process, while we do love developing more features for our customers, one important oversight is we miss testing the performance aspects of our code for what’s called a “software performance regression”.
In simple terms a performance regression causes a noticeable performance dip, which would prove to be a point of annoyance to the end users, if not addressed properly.
As an example in the web development landscape, this lag would manifest in the form an API not responding in time, even worse timing out or it could result in lower throughput rates as a result of more memory consumption.
So we need an automated mechanism through which can repeatedly and reliably measure the performance statistics of our code as part of our software development lifecycle.
Meet BenchmarkDotNet!
BenchmarkDotNet is an open-sourced performance measurement toolkit, that helps .NET developer when looking at performance landscape of their code.
It abstracts out a lot of low-level tasks like performing a pilot experiment and determine the best number of method invocations. Next, it executes several warm-up iterations and ensure that your benchmark achieved a steady state. After that, it executes the main iterations and calculates the performance while sticking to the best scientific statistics for this purpose.
Lets get our hands dirty!
By taking a look at how we can implement our own benchmarks.
A practical example
Let’s say that we are implementing a simple “Contact Book” application and we are trying to solve the problem, where a user would search for a given contact name either fully or partially and we are expected to show the contacts whose names match the given name.
As with all of my other write-ups the code samples used can be found on my github.
https://github.com/Tarun047/ContactListBenchmarkingDemo
For simplicity, let’s say we are looking for all the contacts whose names start with a given prefix.
Let’s start with the data model.
public class Contact
{
public string Name { get; set; }
public string PhoneNumber { get; set; }
public string Email { get; set; }
}As we can see our contact data model is a simple C# class with Name and other contact related properties like PhoneNumber and Email .
Now let’s take a look at how different strategies to solve this problem can be modelled.
Let’s say that all of our solutions implement an interface, so the caller doesn’t need to worry about the implementation details and can easily switch out implementations as needed.
public interface IContactSearcher
{
public IEnumerable<Contact> SearchContactByName(string name);
}As we can see the interface is simple and just has one method which pretty much does what it’s name suggests.
It takes a name and returns all the contacts which having a matching prefix similar to the name.
While we can solve this problem in many ways, I chose to describe some ways, which a typical engineer would consider while solving the problem.
List Based Linear Search
One simple approach, we might consider is add all the contacts into a List and then iterate through the list and filter out those contacts whose names have prefixes same as the given search string.
One way of implementing this could be:
public class ListBasedContactSearcher : IContactSearcher
{
private readonly IReadOnlyList<Contact> _contacts;
public ListBasedContactSearcher(IReadOnlyList<Contact> allContacts)
{
_contacts = allContacts;
}
public IEnumerable<Contact> SearchContactByName(string name)
{
foreach (var contact in _contacts)
{
if (contact.Name.StartsWith(name))
{
yield return contact;
}
}
}
}The Regex Based Search
Another approach that one might take while searching is to construct a regex out of the search string and then filter out those contacts whose names match with the regex.
public class RegexBasedContactSearcher : IContactSearcher
{
private readonly IReadOnlyList<Contact> _contacts;
public RegexBasedContactSearcher(IReadOnlyList<Contact> contacts)
{
_contacts = contacts;
}
public IEnumerable<Contact> SearchContactByName(string name)
{
var regex = new Regex($"^{name}", RegexOptions.Compiled, TimeSpan.FromMinutes(1));
return _contacts.Where(contact => regex.IsMatch(contact.Name));
}
}Trie Based Search
One of the most optimal ways to solve this problem would be to use what’s called a “Trie” data structure.
This name might ring a bell to many CS background people as it’s something which we might have studied back in college.
Without going into too much detail, think of trie as a data-structure which is capable of representing a collection of strings which makes it easy to look-up for either prefixes or suffixes.
A typical implementation for this would look like:
public class TrieBasedContactSearcher : IContactSearcher
{
private readonly Trie<Contact> _trie;
public TrieBasedContactSearcher(IReadOnlyList<Contact> allContacts)
{
_trie = new Trie<Contact>(allContacts);
}
public IEnumerable<Contact> SearchContactByName(string name)
{
return _trie.Search(name);
}
}Essentially the idea is to pre-compute trie prior to our search, so that searches can be massively speeded-up
Hash Based Approach
Another route we can take is to implement a Dictionary where we store a mapping of all prefix strings of contact names to the actual contacts themselves.
public class HashBasedContactSearcher : IContactSearcher
{
private readonly IReadOnlyList<Contact> _contacts;
private readonly Dictionary<ReadOnlyMemory<char>, List<Contact>> _hasher;
public HashBasedContactSearcher(IReadOnlyList<Contact> contacts)
{
_contacts = contacts;
_hasher = new Dictionary<ReadOnlyMemory<char>, List<Contact>>(new ReadOnlyCharMemoryComparer());
PopulateContactHash();
}
private void PopulateContactHash()
{
foreach (var contact in _contacts)
{
for(int i=0; i < contact.IndexKey.Length; i++)
{
var key = contact.IndexKey.AsMemory(0, i+1);
_hasher.TryAdd(key, new List<Contact>());
_hasher[key].Add(contact);
}
}
}
public IEnumerable<Contact> SearchContactByName(string name)
{
return _hasher.TryGetValue(name.AsMemory(), out var matches) ? matches : Enumerable.Empty<Contact>();
}
}In this approach, we simply iterate over the contacts and do another nested loop where we’d iterate over each contact’s name prefix substrings.
Generally we’d want to prefer ReadOnlyMemory<char> over normal substrings to keep our memory footprint small.
Alright now that we have all the different approaches, let’s take a look at how we can write benchmarks for these different approaches.
In BenchmarkDotNet, each benchmark is represented as a simple C# class.
Where each method with a [Benchmark] annotation would be expected to benchmark a given approach.
[MemoryDiagnoser(false)]
[Orderer(SummaryOrderPolicy.Method)]
[RankColumn]
public class ContactSearcherComparisionBenchmark : ContactBookDataGenBase
{
[Benchmark]
public void ListContactSearcher()
{
IContactSearcher contactSearcher = new ListBasedContactSearcher(Contacts);
BenchmarkCore(contactSearcher);
}
[Benchmark]
public void TrieContactSearcher()
{
IContactSearcher contactSearcher = new TrieBasedContactSearcher(Contacts);
BenchmarkCore(contactSearcher);
}
[Benchmark]
public void RegexBasedContactSearcher()
{
IContactSearcher contactSearcher = new RegexBasedContactSearcher(Contacts);
BenchmarkCore(contactSearcher);
}
[Benchmark]
public void HashBasedContactSearcher()
{
IContactSearcher contactSearcher = new HashBasedContactSearcher(Contacts);
BenchmarkCore(contactSearcher);
}
private void BenchmarkCore(IContactSearcher contactSearcher)
{
var matchedContacts = new List<Contact>();
foreach (var name in NamesToSearch)
{
matchedContacts.AddRange(contactSearcher.SearchContactByName(name));
}
}
}Although it looks like writting a simple unit-test, let’s break down the code in simple terms for our understanding.
[MemoryDiagnoser]attribute indicates that we’d also want to capture the memory footprints of each benchmark[Orderer]attribute indicates how do we want to order the results of our benchmark[RankColumn]attribute indicates that we want to have a Rank column which shows the relative execution speeds of these methods ordered from fastest to slowest[Benchmark]column as we’ve already established, tells that this is a Benchmark method.- Each benchmark instantiates an object corresponding to the algorithm it’s testing and passes it to the
BenchmarkCore()method. - In
BenchmarkCore()method we perform the searches on the contact searcher.
Now we’d also need to generate data for testing our benchmarks, one excellent library I’d prefer to use is Bogus.
It’s open-sourced and has nice fluent syntax for facilitating fake data generation.
For each benchmark it makes sense to use the same set of data, to have consistent results, hence we do the data generation only once as done in the base ContactBookDataGenBase class.
public abstract class ContactBookDataGenBase
{
[Params(1_000, 5_000, 10_000)]
public int Size { get; set; }
private readonly Faker<Contact> _faker = new Faker<Contact>()
.UseSeed(42)
.RuleFor(contact => contact.Name, faker => faker.Person.FullName)
.RuleFor(contact => contact.Email, faker => faker.Person.Email)
.RuleFor(contact => contact.PhoneNumber, faker => faker.Person.Phone);
protected List<string> NamesToSearch;
protected List<Contact> Contacts;
[GlobalSetup]
public void Setup()
{
Contacts = _faker.Generate(Size);
NamesToSearch = Enumerable.Range(0, Size).Where(idx => idx % 4 == 0).Select(idx => Contacts[idx].Name).ToList();
Randomizer.Seed = new Random(7337);
var faker = new Faker();
foreach (var contact in Contacts)
{
contact.Name = $"{faker.PickRandom(NamesToSearch)} {contact.Name}";
}
}
}As we can see,
- We use set a seed for repeatable data generation
- The
[Params]annotation indicates that we want to run these benchmarks for different sizes of our contacts, so that we can see how our approach scales as well. - The
[GlobalSetup]annotation indicates that we want to run theSetup()method once before we start any data generation. - In the
Setup()method we generate the fake contact list as per the size and to search for names, we pick 25% of the contacts uniformly distributed in our contact set. - Then we ensure each name in our contact list has a prefix which is pseudo randomly picked from the names to search.
Bring the action!
Now to the benchmarks, we’d have to use one of BenchmarkRunner or BenchmarkSwitcher class.
One important thing to note is that the output type of the project invoking either of these classes should be set to executable.
public class Program
{
public static void Main(string[] args)
{
BenchmarkSwitcher.FromAssembly(typeof(Program).Assembly).Run(args);
}
}For better flexibility I’ve chosen to go with BenchmarkSwitcher , as it allows us to run any benchmarks we want selectively through command line arguments.
To see it in action, all we have to do is from the root level of our repo run the following command
dotnet run -c Release --project ContactBook.Benchmark --filter ContactBook.Benchmark.Comparision*And wait for the benchmarking to be complete.
It’s worth knowing that BenchmarkDotnet does a lot of things to correct benchmarking like:
- Setting up the OS power plan to favor performance
- Most modern computers come with special hardware features to optimize the execution process, this means that instructions might get re-ordered/cached depending on the need.
- Similarly dotnet itself comes with what’s called a Just-In-Time Compiler, which compiles and optimizes a given code path for better performance at various levels, depending on various factors like frequency of execution.
- To eliminate such variables, it’s necessary to run the benchmarks a couple of times to ensure that our code is running on the most optimal path it can be given, these can be seen in various stages of BenchmarkDotnet’s output like OverheadJitting & WorkloadJitting, WorkloadPilot, OverheadWarmup, OverheadActual.
- WorkloadActual indicates that actual benchmark execution has started.
Once it’s done, you’ll be greeted with nicely summarized benchmark results like:
| Method | Size | Mean | Error | StdDev | Rank | Allocated |
|-------------------------- |------ |-------------:|-----------:|-----------:|-----:|------------:|
| HashBasedContactSearcher | 1000 | 8.862 ms | 0.1679 ms | 0.1649 ms | 1 | 3118.33 KB |
| HashBasedContactSearcher | 5000 | 64.380 ms | 1.2781 ms | 1.5215 ms | 4 | 20296.8 KB |
| HashBasedContactSearcher | 10000 | 117.330 ms | 2.1615 ms | 2.4025 ms | 6 | 29923.81 KB |
| ListContactSearcher | 1000 | 9.436 ms | 0.1761 ms | 0.3038 ms | 2 | 41.64 KB |
| ListContactSearcher | 5000 | 245.887 ms | 2.2407 ms | 1.9863 ms | 9 | 255.83 KB |
| ListContactSearcher | 10000 | 1,091.802 ms | 20.3501 ms | 16.9933 ms | 10 | 511.38 KB |
| RegexBasedContactSearcher | 1000 | 206.909 ms | 1.2950 ms | 1.2114 ms | 8 | 2197.3 KB |
| RegexBasedContactSearcher | 5000 | 1,432.635 ms | 7.5883 ms | 7.0981 ms | 11 | 11035.85 KB |
| RegexBasedContactSearcher | 10000 | 4,044.368 ms | 31.2489 ms | 27.7013 ms | 12 | 22071.6 KB |
| TrieContactSearcher | 1000 | 9.849 ms | 0.1967 ms | 0.4899 ms | 3 | 7016.96 KB |
| TrieContactSearcher | 5000 | 101.423 ms | 2.0266 ms | 3.4414 ms | 5 | 34676.31 KB |
| TrieContactSearcher | 10000 | 202.951 ms | 3.5387 ms | 4.2126 ms | 7 | 68817.95 KB |As you can see, with respect to the time taken, we notice that
HashBasedContactSearcher (Best) < TrieBasedContactSearcher < ListBasedContactSearcher < RegexBasedContactSearcher (Worst)
Similarly with space we observe that
ListBasedContactSearcher (Best) < RegexBasedContactSearcher < HashBasedContactSearcher < TrieBasedContactSearcher (Worst)
Now we can make an informed decision on which approach to choose depending on our needs.
Bonus!
If you’ve read the write-up till here, you really care about performance and kudos for that!
As a bonus section, I’ve included one simple way to integrate performance testing as part of our CI pipelines.
At the time of writing, BenchmarkDotNet doesn’t officially have a way to integrate with CI pipelines.
However massive shout-out to @adamsitnik and other OSS contributors to the dotnet performance repo.
We’ve gotten good comparison tool that can easily compare the results of these benchmarks.
With minor tweaks we can utilize this tool for our use case.
We can set-up our pipeline as follows:
- Identify the performance critical paths in our code and write benchmark classes for them.
- Whenever a push is made on master branch, we can trigger a github workflow that builds our code, runs our unit tests and also runs our performance related benchmarks and saves the results as artifacts for future reference as descibed in below github action
name: Benchmark Main
on:
push:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest # For a list of available runner types, refer to
# https://help.github.com/en/actions/reference/workflow-syntax-for-github-actions#jobsjob_idruns-on
steps:
- name: Checkout
uses: actions/checkout@v4
with:
fetch-depth: 0
# Install the .NET Core workload
- name: Install .NET Core
uses: actions/setup-dotnet@v3
with:
dotnet-version: 8.0.x
# Execute all unit tests in the solution
- name: Execute unit tests
run: dotnet test
# Run benchmarks
- name: Run Benchmarks
run: dotnet run -c Release --project ContactBook.Benchmark --filter ContactBook.Benchmark.Features* --artifacts BenchmarkDotNet.Artifacts.Main
# Upload the Results: https://github.com/marketplace/actions/upload-a-build-artifact
- name: Upload benchmark artifacts
uses: actions/upload-artifact@v3
with:
name: Benchmark Artifacts Main
path: BenchmarkDotNet.Artifacts.Main- Similarly whenever someone makes a PR to our github repo we run the benchmarks both on current PR’s branch and also main branch.
Although github’s runners aren’t going to be drastically different from run-to-run.
It’s best to run benchmarks on the same hardware to extract meaningful difference
name: .NET Core Perf Regression
on:
pull_request:
branches: [ "main" ]
jobs:
benchmark:
runs-on: ubuntu-latest # For a list of available runner types, refer to
# https://help.github.com/en/actions/reference/workflow-syntax-for-github-actions#jobsjob_idruns-on
steps:
- name: Checkout
uses: actions/checkout@v4
with:
fetch-depth: 0
# Install the .NET Core workload
- name: Install .NET Core
uses: actions/setup-dotnet@v3
with:
dotnet-version: 8.0.x
# Run benchmarks
- name: Run Benchmarks on Current Branch
run: dotnet run -c Release --project ContactBook.Benchmark --filter ContactBook.Benchmark.Features* --artifacts BenchmarkDotNet.Artifacts.Current
# Upload the Results: https://github.com/marketplace/actions/upload-a-build-artifact
- name: Upload current benchmark artifacts
uses: actions/upload-artifact@v3
with:
name: BenchmarkDotNet.Artifacts.Current
path: BenchmarkDotNet.Artifacts.Current
# Checkout to main branch
- name: Checkout to main branch
uses: actions/checkout@v4
with:
ref: main
clean: false
# Run benchmarks on main branch
- name: Run Benchmarks on Main
run: dotnet run -c Release --project ContactBook.Benchmark --filter ContactBook.Benchmark.Features* --artifacts BenchmarkDotNet.Artifacts.Main
# Upload the Results: https://github.com/marketplace/actions/upload-a-build-artifact
- name: Upload main benchmark artifacts
uses: actions/upload-artifact@v3
with:
name: BenchmarkDotNet.Artifacts.Main
path: BenchmarkDotNet.Artifacts.Main
# Compare the benchmarks
- name: Compare Benchmarks
run: dotnet run -c Release --project ContactBook.BenchmarkResultsComparer --base BenchmarkDotNet.Artifacts.Main --diff BenchmarkDotNet.Artifacts.Current --threshold 10%And that’s all we’ll need for our CI setup.
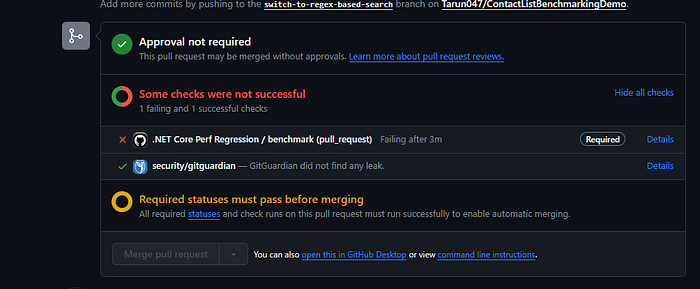
Now let’s say that someone makes a change to degrade performance like the one on this pull request
We can see that the merging is blocked because our checks failed.
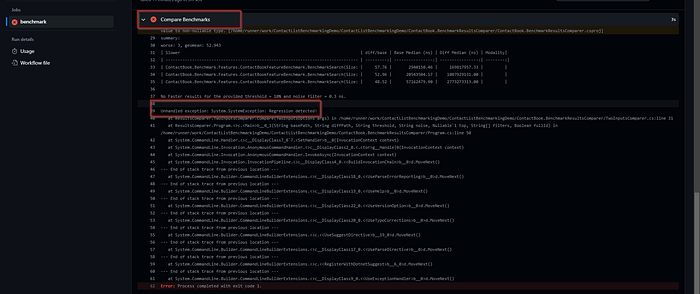
And when we see the failed check, we find it is because of performance regression.
Anyway thought I’d share something I found very interesting, that’s it for this story, thanks for making it till here 😄.
Connect with me on LinkedIn and X
for more such interesting reads.
References: